Demystifying Connection Pools: A Deep Dive

Experienced Software Engineer with a demonstrated history of working in the Storage, Security and Wireless industries.
Connection pools are a critical aspect of software engineering that allows applications to efficiently manage connections to a database or any other system. If your application requires constant access to a system, establishing a new connection to the system for every request can quickly become resource-intensive, causing your application to slow down or even crash. This is where connection pools come in.
As engineers, we often don't spend a lot of time thinking about connections. A single connection is typically inexpensive, but as things scale up, the cost of creating and maintaining these connections increase accordingly. This is why I believe understanding the world of connection pooling is important as it will enable us to build more performant and reliable applications, especially at scale.
Typical connections
Before jumping to connection pooling, let us understand how an application typically connects to a system to perform any operation:
The application attempts to open a connection.
A network socket is opened to connect the application to the system.
Authentication is performed.
Operation is performed.
Connection is closed.
Socket is closed.
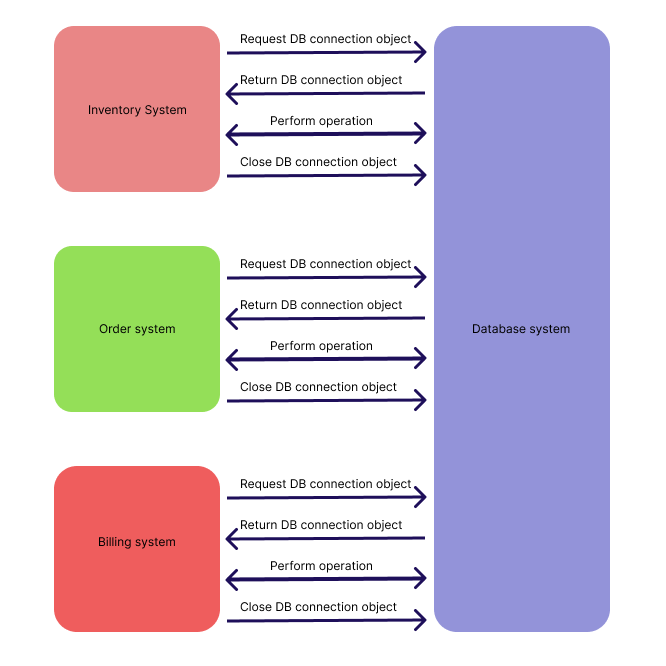
As you can see, opening and closing the connection and the network socket is a multi-step process that requires resource computation. However, not closing the connection, or keeping it idle also consumes resources. This is why we need connection pooling. While you will mostly see connection pooling being used in database systems, the concept can be extended to any application which communicates with a remote system over a network.
What are Connection Pools?
Connection pools are typically a cache of connections that can be reused by an application. Instead of creating a new connection each time an application needs to interact with the system, a connection is borrowed from the pool, and when it's no longer needed, it is returned to the pool to be reused later. This approach ensures that the application always has access to a ready-to-use connection, without the need to create new connections continuously.
Connection pooling reduces the cost of opening and closing connections by maintaining a “pool” of open connections that can be passed from one operation to another as needed. This way, we are spared the expense of having to open and close a brand new connection for each operation the system is asked to perform.
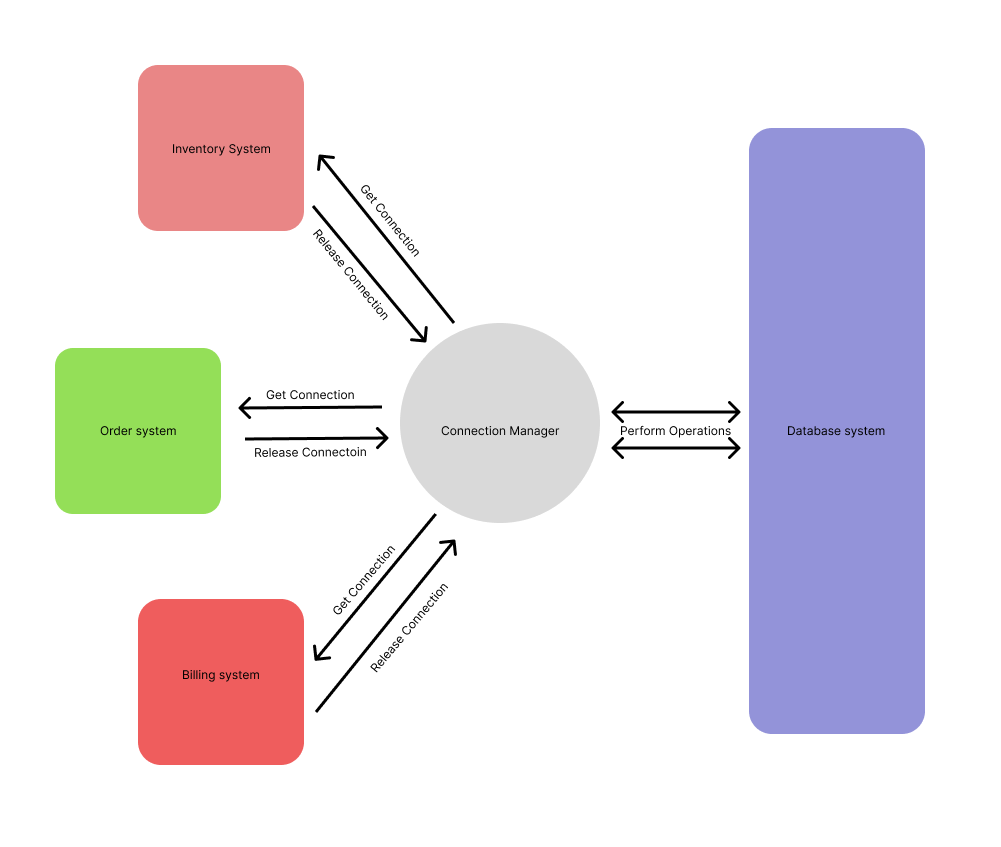
In this blog post, we'll demystify connection pools, explain how they work, how to implement them, and explore some of the common issues associated with connection pools. We'll also discuss connection pooling in the cloud and why it's important for modern-day applications. By the end of this blog post, you should have a good understanding of connection pools and how they can help you build more efficient and robust applications.
How Connection Pools Work
The basic principle of connection pooling is to maintain a pool of connections that are ready for use, rather than creating and destroying connections as required. When a client requests a connection from the pool, the connection pool manager checks if there are any available connections in the pool. If an available connection exists, the connection pool manager returns the connection to the client. Otherwise, the connection pool manager creates a new connection, adds it to the pool, and returns the new connection to the client.
Connection pooling algorithms are used to manage the pool of connections. These algorithms determine when to create new connections and when to reuse existing connections. The most common algorithms used for connection pooling are LRU (Least Recently Used), and round-robin or FIFO (First In, First Out).
In LRU, the connection pool manager keeps track of the time that each connection was last used. When a new connection is required, the connection pool manager selects the least recently used connection from the pool and returns it to the user.
In FIFO, the connection pool manager manages connections in the order they were added to the pool. When a new connection is required, the connection pool manager selects the connection that has been in the pool the longest and returns it to the user.
Connection pooling configurations are used to set the parameters for the connection pool. These configurations include settings such as the minimum and maximum number of connections in the pool, the maximum time a connection can be idle before it is closed, and the maximum time a connection can be used before it is returned to the pool.
Overall, the basic principles of connection pooling involve creating a pool of database connections, managing the pool using algorithms and configurations, and reusing the connections as required to reduce overhead and improve performance.
Implementing Our Own Connection Pool
To implement connection pooling in a specific programming language or framework, developers typically use connection pool libraries or built-in connection pool features. Code snippets and examples for implementing connection pools are often available in library documentation or online resources.
However, simply integrating an existing library in some dummy application is no good for us. Additionally, as a software engineer, implementing our own connection pool can bring a wealth of knowledge benefits. Firstly, it can significantly improve the performance of our application by reducing the overhead associated with establishing new connections. Additionally, it can help to prevent connection leaks and other issues that can arise from improperly managed connections.
Moreover, it provides us with fine-grained control over connection creation, usage, and destruction, allowing us to optimize our application's resource utilization. By implementing our own connection pooling, we can gain a deeper understanding of how our application works and thereby improve its scalability and reliability.
Building Blocks
For ease of demonstration, we can use SQLite3 DB and implement our own custom pooling for the same. I'll be using Go language here because of its simplicity. You can use any language of your choice.
To start with, our ConnectionPool struct will look something like this:
type ConnectionPool struct {
queue chan *sql.DB
maxSize int
currentSize int
lock sync.Mutex
isNotFull *sync.Cond
isNotEmpty *sync.Cond
}
Here, the ConnectionPool struct contains the queue, maxSize, currentSize, lock, isNotFull, and isNotEmpty fields. The queue field is a channel that holds pointers to sql.DB connections. sql.DB type belongs to Go's built in database/sql package. The database/sql provides a generic interface around SQL or SQL-like databases. This interface is implemented by the github.com/mattn/go-sqlite3 package which we will be using as an SQLite3 driver.
The maxSize field represents the maximum number of connections that the pool can have, and the currentSize field represents the current number of connections in the pool. The lock field is a mutex that ensures that concurrent access to shared memory is synchronized. The isNotFull and isNotEmpty fields are condition variables that allow for efficient waiting and are used to signal when the pool is not full and not empty, respectively.
sync.Cond is a synchronization primitive in Go that allows multiple goroutines to wait for a shared condition to be satisfied. It is often used in conjunction with a mutex, which provides exclusive access to a shared resource (in this case the queue), to coordinate the execution of multiple goroutines.
Yes. Channels can also be used for synchronization, but they come with some overhead in terms of memory usage and complexity. In this case, the use of sync.Cond provides a simpler and more lightweight alternative as they allow for efficient signaling for waiting goroutines.
By using sync.Cond, the implementation can ensure that goroutines waiting on the condition will be woken up only when the condition is actually met, rather than relying on a buffer channel that might have stale data. This improves the overall performance and reduces the likelihood of race conditions or deadlocks.
Getting Connection Object from the Pool
Next, we will implement a Get method which will return a database object from an existing ConnectionPool:
func (cp *ConnectionPool) Get() (*sql.DB, error) {
cp.lock.Lock()
defer cp.lock.Unlock()
// If queue is empty, wait
for cp.currentSize == 0 {
fmt.Println("Waiting for connection to be added back in the pool")
cp.isNotEmpty.Wait()
}
fmt.Println("Got connection!! Releasing")
db := <-cp.queue
cp.currentSize--
cp.isNotFull.Signal()
err := db.Ping()
if err != nil {
return nil, err
}
return db, nil
}
This function, Get(), retrieves a connection from the pool. First, it acquires the lock to ensure exclusive access to the shared state of the connection pool. If the pool is currently empty, the function waits until a connection is added back to the pool.
Once a connection is available, the function dequeues it from the queue, decrements currentSize, and signals that the pool is not full. It then checks whether the connection is still valid by calling Ping(). If the connection is not valid, an error is returned, and the connection is not returned to the caller. If the connection is valid, it is returned to the caller.
Adding Connection Object to the Pool
Moving on, we add an Add method whose responsibility will be to add the connection object to the pool once it has been used:
func (cp *ConnectionPool) Add(db *sql.DB) error {
if db == nil {
return errors.New("database not yet initiated. Please create a new connection pool")
}
cp.lock.Lock()
defer cp.lock.Unlock()
for cp.currentSize == cp.maxSize {
fmt.Println("Waiting for connection to be released")
cp.isNotFull.Wait()
}
cp.queue <- db
cp.currentSize++
cp.isNotEmpty.Signal()
return nil
}
This function, Add(), adds a connection to the pool. It first checks whether the connection is nil and returns an error if it is. Then, it acquires the lock to ensure exclusive access to the shared state of the connection pool. If the pool is currently full, the function waits until a connection is released from the pool.
Once there is space in the pool, the function enqueues the connection onto the queue, increments currentSize, and signals that the pool is not empty. The function returns nil to indicate success
Closing the Connection Pool
As the name suggests, we will implement a Close function which will be responsible for closing all database connections in the pool. It starts by acquiring a lock and then it iterates through the all connections in the pool and closes them one by one. After closing each connection, it decrements the currentSize counter and signals any waiting goroutines that there is space that is now available in the pool.
func (cp *ConnectionPool) Close() {
cp.lock.Lock()
defer cp.lock.Unlock()
for cp.currentSize > 0 {
db := <-cp.queue
db.Close()
cp.currentSize--
cp.isNotFull.Signal()
}
close(cp.queue)
}
Initializing the Connection Pool
We will implement a NewConnectionPool function as a constructor for a new connection pool. It takes the driver, dataSource, and maxSize arguments and returns a pointer to a new ConnectionPool instance. It first checks if the provided driver and dataSource arguments are valid by opening a connection to the database. If the connection is successful, it initializes a new connection pool with the provided maxSize argument. It then creates a new channel of *sql.DB objects and pre-populates it with maxSize database connections by creating a new database connection for each iteration of a loop. Finally, it returns the new ConnectionPool instance.
func NewConnectionPool(driver, dataSource string, maxSize int) (*ConnectionPool, error) {
// Validate driver and data source
_, err := sql.Open(driver, dataSource)
if err != nil {
return nil, err
}
cp := &ConnectionPool{
queue: make(chan *sql.DB, maxSize),
maxSize: maxSize,
currentSize: 0,
}
cp.isNotEmpty = sync.NewCond(&cp.lock)
cp.isNotFull = sync.NewCond(&cp.lock)
for i := 0; i < maxSize; i++ {
conn, err := sql.Open(driver, dataSource)
if err != nil {
return nil, err
}
cp.queue <- conn
cp.currentSize++
}
return cp, nil
}
Putting it All Together
This is what our final custom Connection Pool implementation looks like:
package pool
import (
"database/sql"
"errors"
"fmt"
"sync"
_ "github.com/mattn/go-sqlite3"
)
type ConnectionPool struct {
queue chan *sql.DB
maxSize int
currentSize int
lock sync.Mutex
isNotFull *sync.Cond
isNotEmpty *sync.Cond
}
func (cp *ConnectionPool) Get() (*sql.DB, error) {
cp.lock.Lock()
defer cp.lock.Unlock()
// If queue is empty, wait
for cp.currentSize == 0 {
fmt.Println("Waiting for connection to be added back in the pool")
cp.isNotEmpty.Wait()
}
fmt.Println("Got connection!! Releasing")
db := <-cp.queue
cp.currentSize--
cp.isNotFull.Signal()
err := db.Ping()
if err != nil {
return nil, err
}
return db, nil
}
func (cp *ConnectionPool) Add(db *sql.DB) error {
if db == nil {
return errors.New("database not yet initiated. Please create a new connection pool")
}
cp.lock.Lock()
defer cp.lock.Unlock()
for cp.currentSize == cp.maxSize {
fmt.Println("Waiting for connection to be released")
cp.isNotFull.Wait()
}
cp.queue <- db
cp.currentSize++
cp.isNotEmpty.Signal()
return nil
}
func (cp *ConnectionPool) Close() {
cp.lock.Lock()
defer cp.lock.Unlock()
for cp.currentSize > 0 {
db := <-cp.queue
db.Close()
cp.currentSize--
cp.isNotFull.Signal()
}
close(cp.queue)
}
func NewConnectionPool(driver, dataSource string, maxSize int) (*ConnectionPool, error) {
// Validate driver and data source
_, err := sql.Open(driver, dataSource)
if err != nil {
return nil, err
}
cp := &ConnectionPool{
queue: make(chan *sql.DB, maxSize),
maxSize: maxSize,
currentSize: 0,
}
cp.isNotEmpty = sync.NewCond(&cp.lock)
cp.isNotFull = sync.NewCond(&cp.lock)
for i := 0; i < maxSize; i++ {
conn, err := sql.Open(driver, dataSource)
if err != nil {
return nil, err
}
cp.queue <- conn
cp.currentSize++
}
return cp, nil
}
Of course, there are many ways in which this implementation can be improved upon. Typically, you can use any variation of the Bounded-queue to implement your own connection pool. Most connection pool implementation use Bounded-queue as the underlying data structure.
The complete implementation along with its usage is open-sourced here in case you wish to play around. I'll suggest running it in debug mode to watch the signaling magic of sync.Cond unfold.
Common Connection Pooling Issues
While connection pooling can bring many benefits to an application, it is not without its challenges. Here are some common issues that can arise with connection pooling:
Overuse of Connection Pools: Connection pools should be used judiciously, as an overuse of pools can result in a decrease in application performance. This is because the connection pool itself can become a bottleneck if too many connections are being opened and closed, causing delays in database transactions.
Pool Size Configuration Errors: Connection pool size is an important consideration when implementing connection pooling. If the pool size is too small, there may not be enough connections available to handle peak traffic, resulting in errors or delays. On the other hand, if the pool size is too large, it can lead to unnecessary resource consumption and potential performance issues.
Connection Leaks: Connection leaks occur when a connection is not properly closed and returned to the pool after it has been used. This can lead to resource exhaustion, as unused connections will remain open and tie up valuable resources. Over time, this can result in degraded application performance and, in extreme cases, cause the application to crash.
To avoid these issues, it is important to monitor connection pool usage and performance regularly. Best practices such as setting appropriate pool size, tuning timeout and idle settings, and configuring automatic leak detection and recovery can help minimize the impact of these issues. Additionally, logging and alerting mechanisms can be put in place to help identify and remediate any issues that do occur.
Connection Pooling in Cloud Environments
Connection pooling is an important consideration when designing applications for the cloud. Cloud environments offer several unique challenges, such as elastic scalability and dynamic resource allocation. Connection pooling can help address some of these challenges, but there are additional considerations to take into account.
In a cloud environment, applications may be running on multiple instances or virtual machines. This means that a single connection pool may not be sufficient to handle the load from all of these instances. Instead, it may be necessary to implement multiple connection pools, each handling a subset of the total workload.
Another consideration is the dynamic nature of cloud environments. Instances can be added or removed from the environment at any time, which means that the size of the connection pool may need to be adjusted accordingly. This can be achieved through automation tools or by implementing dynamic scaling rules based on metrics such as CPU usage or network traffic.
Security is also an important consideration when implementing connection pooling in the cloud. In a shared environment, it is important to ensure that connections are secure and cannot be accessed by unauthorized parties. This may involve implementing encryption or access control measures, such as IP filtering.
Finally, it is important to ensure that connection pooling is properly configured for the specific cloud environment being used. Each cloud provider may have its own specific requirements and recommendations for connection pooling, such as maximum pool size or connection timeouts. It is important to consult the provider's documentation and best practices guides to ensure that connection pooling is properly configured for optimal performance and reliability.
In summary, connection pooling can be a valuable tool for optimizing performance and managing resources in cloud environments. However, there are additional considerations that must be taken into account to ensure that connection pooling is properly implemented and configured for the specific cloud environment being used.
Final Thoughts
In conclusion, connection pooling is a crucial concept in modern software development that can help to improve application performance and scalability while reducing resource usage. By caching and reusing database connections, connection pooling can reduce the overhead of creating and destroying connections, leading to faster application response times and increased throughput.
However, connection pooling is not a silver bullet and must be used carefully and thoughtfully. Common issues such as overuse of connection pools, pool size configuration errors, and connection leaks can cause performance degradation and even application crashes.
When using connection pooling in cloud environments, additional considerations must be taken into account, such as the network latency between the application and the database, and the dynamic nature of cloud resources.
To sum up, connection pooling is an important tool for improving database performance in modern software applications. By understanding how connection pooling works, common issues to look out for, and best practices for implementation, software engineers can harness the power of connection pooling to build more performant, scalable, and reliable applications.



